Friendli Fine-Tuning
How to Fine-tune Vision Language Models (VLMs)
Fine-tune Vision Language Models (VLMs) on Friendli Dedicated Endpoints using datasets.
Introduction
Effortlessly fine-tune your Vision Language Model (VLM) with Friendli Dedicated Endpoints, which leverages the Parameter-Efficient Fine-Tuning (PEFT) method to reduce training costs while preserving model quality, similar to full-parameter fine-tuning. This can make your model become an expert on specific visual tasks and improve its ability to understand and describe images accurately. In this tutorial, we will cover:- How to upload your image-text dataset for VLM fine-tuning.
- How to fine-tuning state-of-the-art VLMs like Qwen2.5-VL-32B-Instruct and gemma-3-27b-it on your dataset.
- How to deploy your fine-tuned VLM model.
Table of Contents
- Prerequisites
- Step 1. Prepare Your Dataset
- Step 2. Upload Your Dataset
- Step 3. Fine-tune Your VLM
- Step 4. Monitor Training Progress
- Step 5. Deploy Your Fine-tuned Model
- Resources
Prerequisites
- Head to Friendli Suite and create an account.
- Issue a Friendli Token by going to Personal settings > Tokens.
Make sure to copy and store it securely in a safe place as you won’t be able to see it again after refreshing the page.
For detailed instructions, see Personal Access Tokens.
Step 1. Prepare Your Dataset
Your dataset should be a conversational dataset in.jsonl or .parquet format, where each line represents a sequence of messages. Each message in the conversation should include a "role" (e.g., system, user, or assistant) and "content". For VLM fine-tuning, user content can contain both text and image data (Note that for image data, we support URL and Base64).
Here’s an example of what it should look like. Note that it’s one line but beautified for readability:
You can access our example dataset ‘FriendliAI/gsm8k’ (for Chat), ‘FriendliAI/sample-vision’ (for Chat with image) and explore some of our quantized generative AI models on our Hugging Face page.
Step 2. Upload Your Dataset
Once you have prepared your dataset, you can upload it to Friendli using the Python SDK.Install the Python SDK
First, install the Friendli Python SDK:Upload Your Dataset
Use the following code to create a dataset and upload your samples:How It Works
Friendli Python SDK doesn’t upload your entire dataset file at once. Instead, it processes your dataset more efficiently:-
Reads your dataset file line by line: Each line is parsed as a
Sampleobject containing a conversation with messages. -
Creates a dataset: A new dataset is created in your Friendli project with the specified modalities (
TEXTandIMAGE). - Uploads each conversation as a separate sample: Rather than uploading the entire file, each conversation (line in the dataset file) becomes an individual sample in the dataset.
- Organizes by splits: Samples are organized into splits like “train”, “validation”, or “test” for different purposes during fine-tuning.
Environment Variables
Make sure to set the required environment variables:https://friendli.ai/<teamId>/<projectId>/....
View Your Dataset
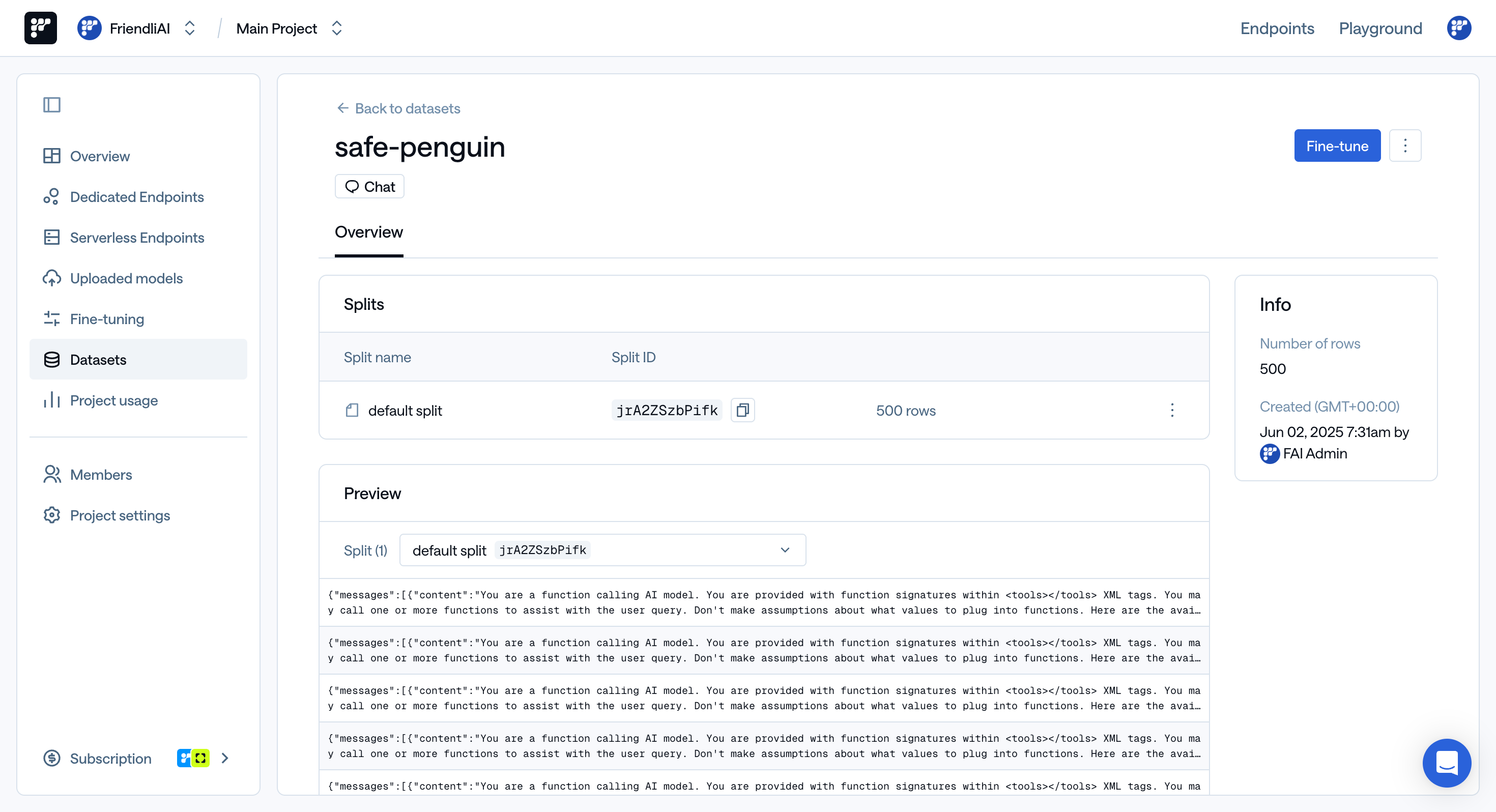
To view and edit the datasets you’ve uploaded, visit Friendli Suite > Dataset.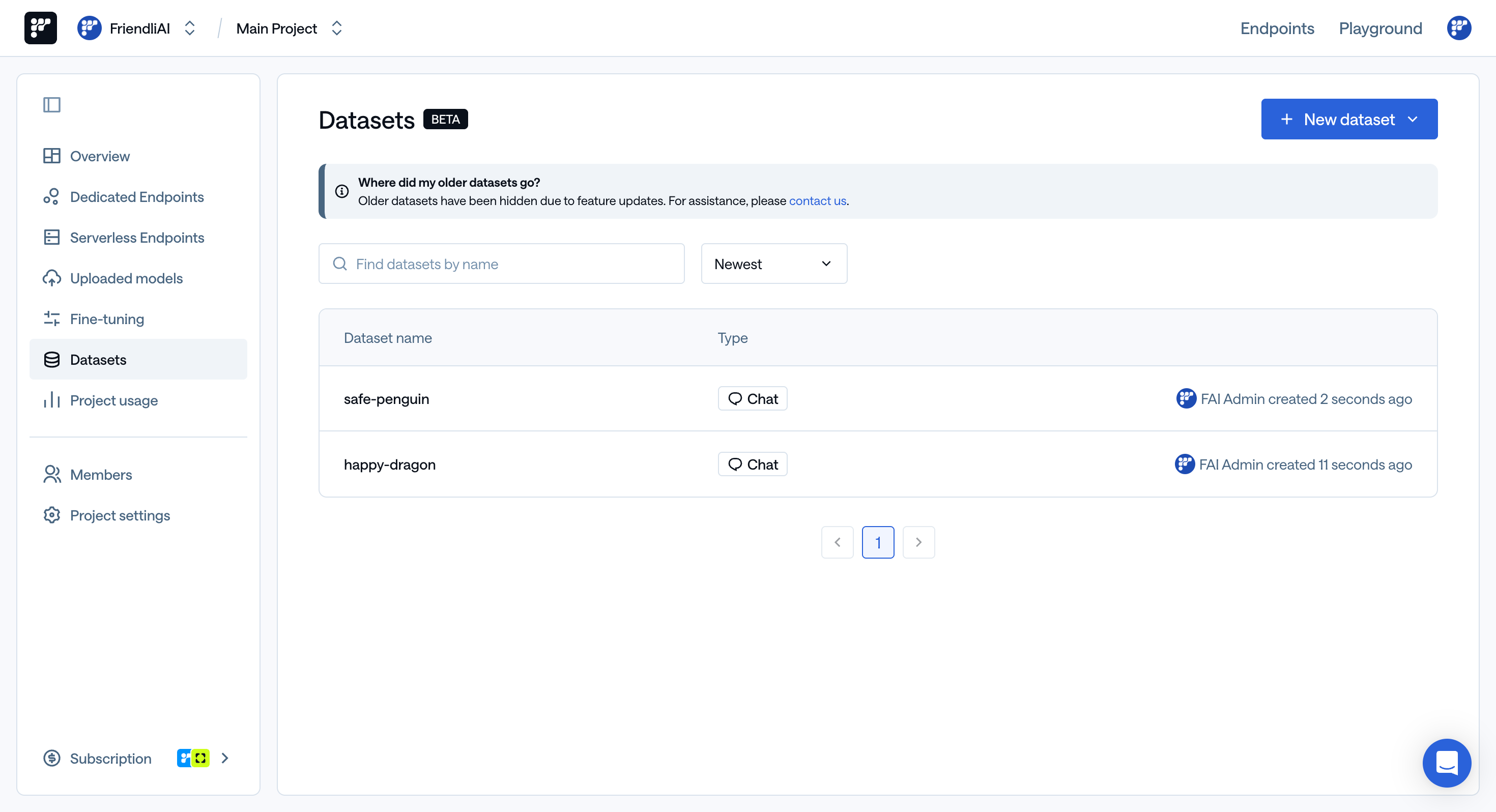
Step 3. Fine-tune Your VLM
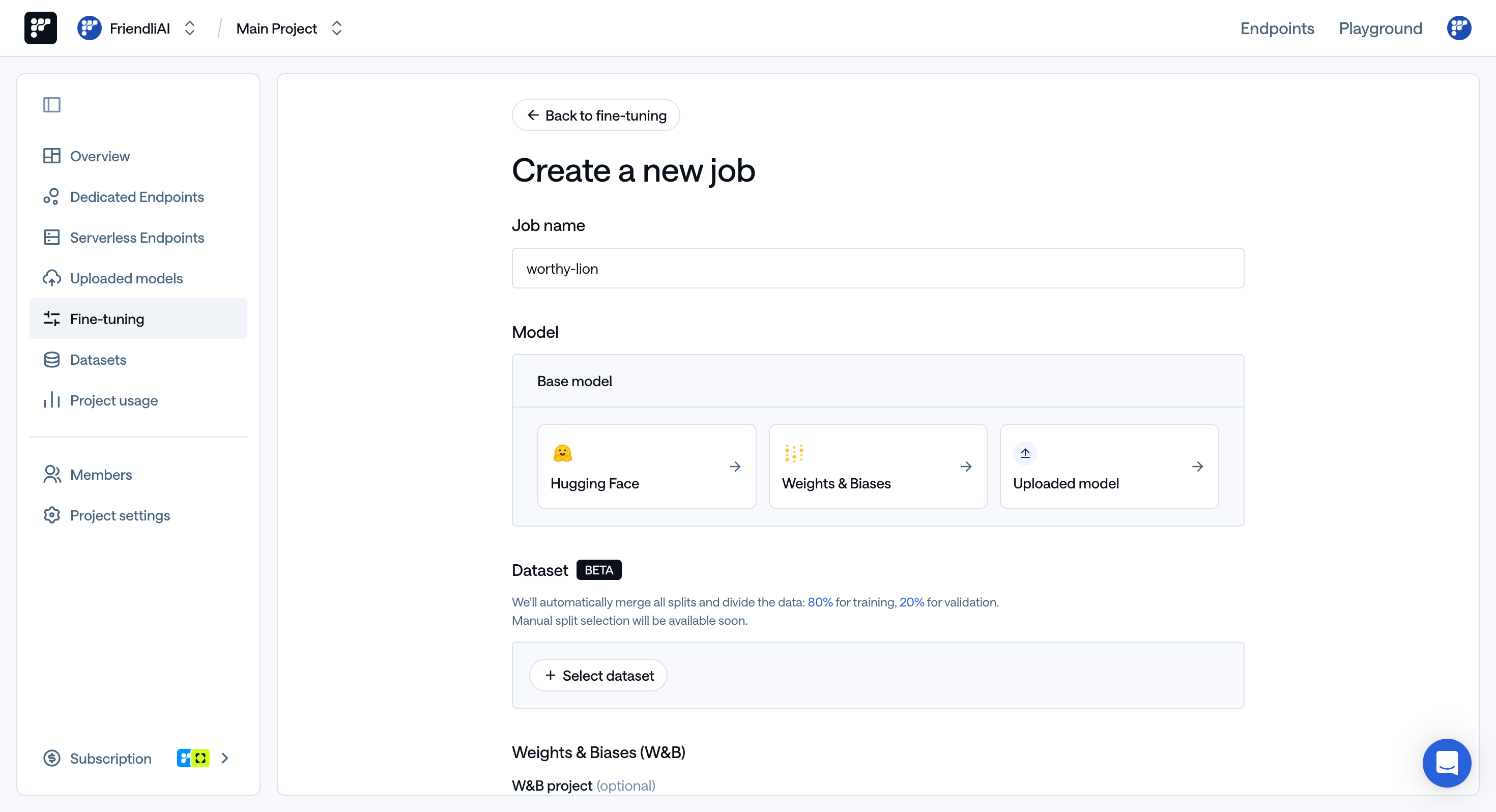
Go to Friendli Suite > Fine-tuning, and click the ‘New job’ button to create a new job.
-
Job Name:
- Enter a name for your fine-tuning job.
- If not provided, a name will be automatically generated (e.g.,
accomplished-shark).
-
Model:
- Choose your base model from one of these sources:
- Hugging Face: Select from models available on Hugging Face.
- Weights & Biases: Use a model from your W&B projects.
- Uploaded model: Use a model you’ve previously uploaded.
- Choose your base model from one of these sources:
-
Dataset:
- Select the dataset to use.
-
Weights & Biases Integration (Optional):
- Enable W&B tracking by providing your W&B project name.
- This will automatically log training metrics to your W&B dashboard for comprehensive monitoring and experiment tracking.
- For detailed setup instructions, see using W&B with dedicated fine-tuning.
-
Hyperparameters:
- Learning Rate (required): Initial learning rate for optimizer (e.g., 0.0001).
- Batch Size (required): Total batch size used for training (e.g., 16).
- Total Number of Training (required), either:
- Number of Training Epoch: Total number of training epochs to perform (e.g., 1)
- Training Steps: Total number of training steps to perform (e.g., 1000)
- Evaluation Steps (required): Number of steps between evaluation of the model using the validation set (e.g., 300).
- LoRA Rank (optional): Rank of the LoRA parameters (e.g., 16).
- LoRA Alpha (optional): Scaling factor that determines the influence of the low-rank matrices during fine-tuning (e.g., 32).
- LoRA Dropout (optional): Dropout rate applied during fine-tuning (e.g., 0.1).
Step 4. Monitor Training Progress
You can now monitor your fine-tuning job progress and on Friendli Suite. If you have integrated your Weights & Biases (W&B) account, you can also monitor the training status in your W&B project. Read our FAQ section on using W&B with dedicated fine-tuning to learn more about monitoring you fine-tuning jobs on their platform.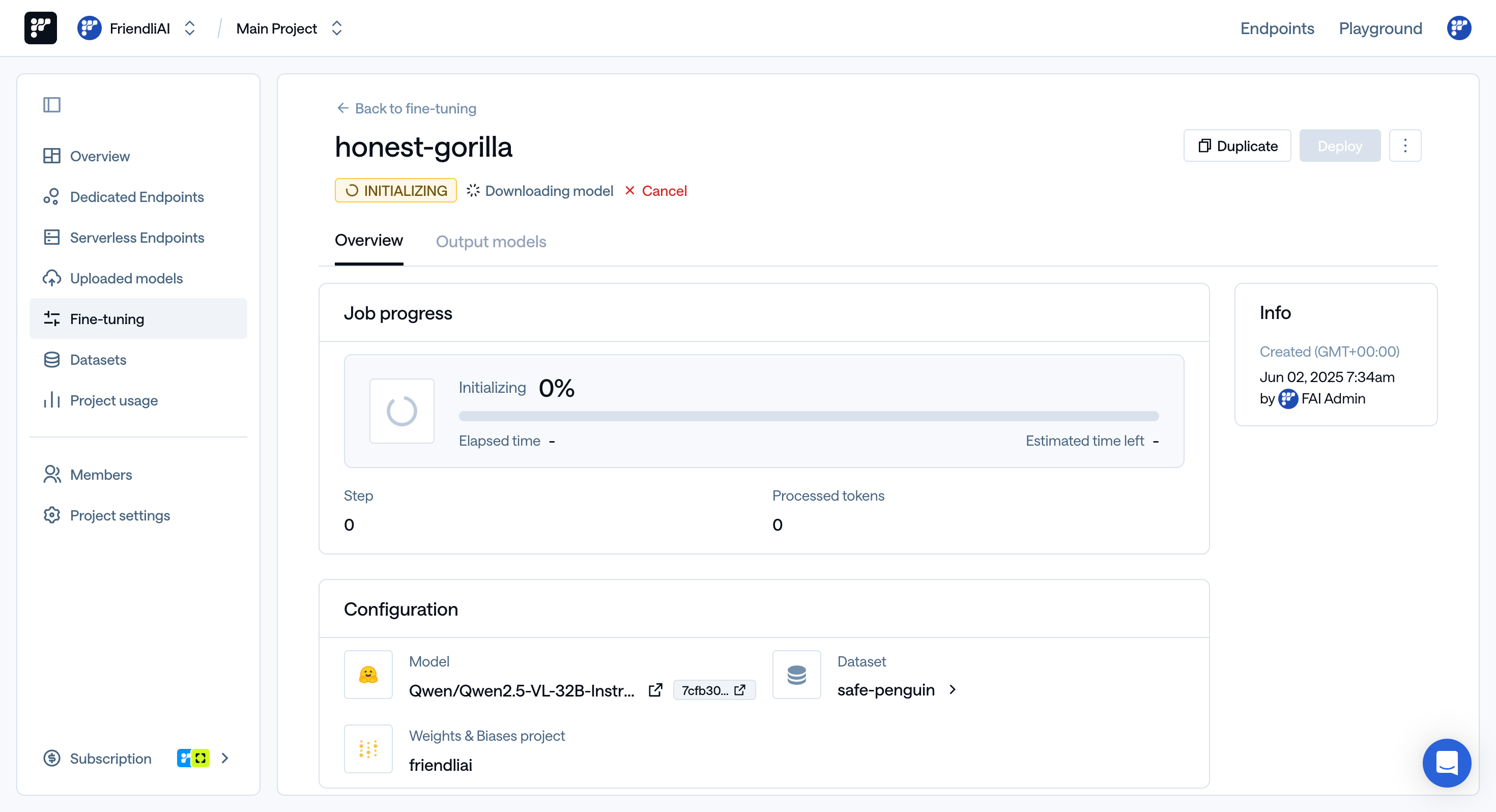
Step 5. Deploy Your Fine-tuned Model
Once the fine-tuning process is complete, you can immediately deploy the model by clicking the ‘Deploy’ button in the top right corner. The name of the fine-tuned LoRA adapter will be the same as your fine-tuning job name.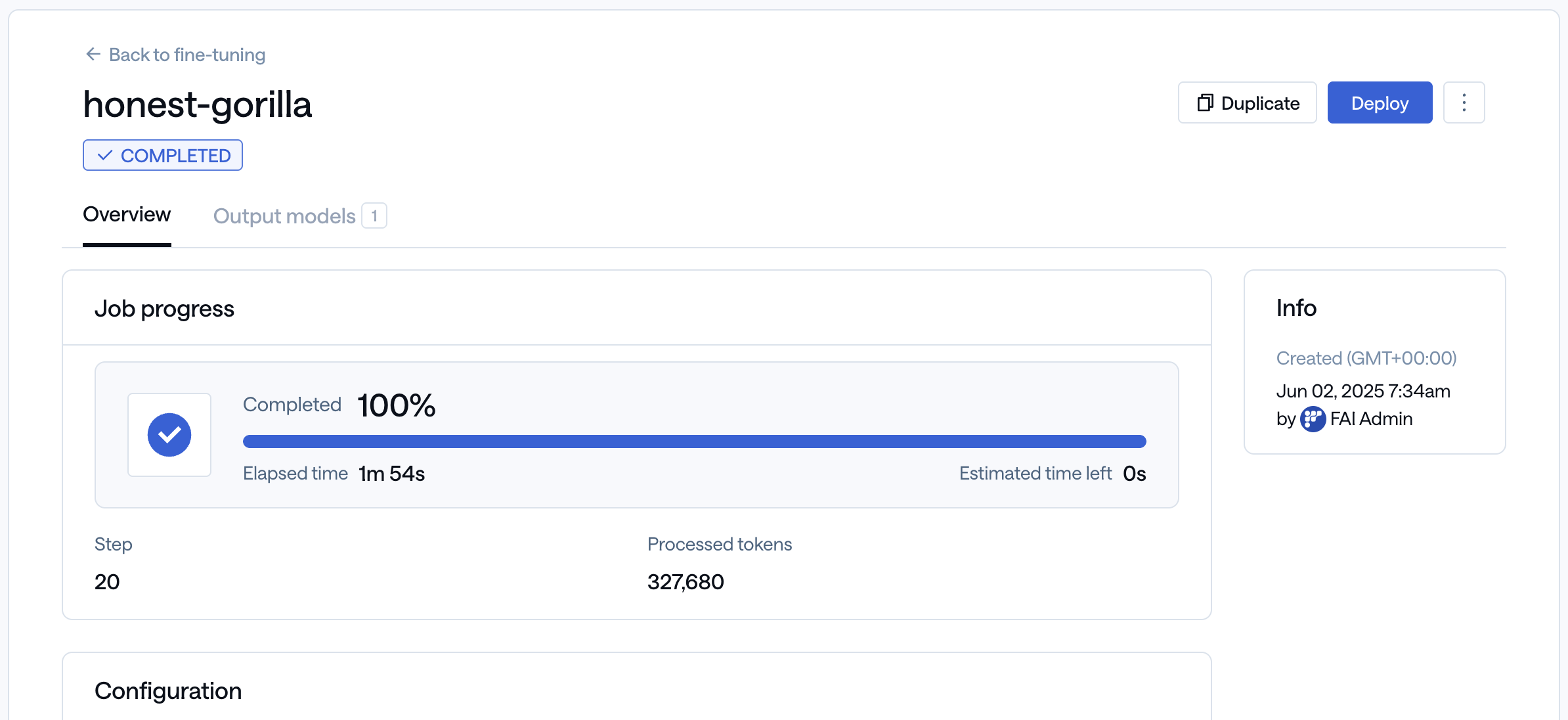
Resources
Explore these additional resources to learn more about VLM fine-tuning and optimization:- Browse all models supported by FriendliAI
- Example dataset
- FAQ on general requirements for a model
- FAQ on using a Hugging Face repository as a model
- FAQ on integrating a Hugging Face account
- FAQ on using a W&B artifact as a model
- FAQ on integrating a W&B account
- FAQ on using W&B with dedicated fine-tuning
- Endpoints documentation on model deployment