Friendli Fine-Tuning
Fine-tuning
Effortlessly fine-tune your model with Friendli Dedicated Endpoints, which leverages the Parameter-Efficient Fine-Tuning (PEFT) method to reduce training costs while preserving model quality, similar to full-parameter fine-tuning.
In order to fine-tune large generic models for your specific purpose, you may fine-tune models on Friendli Dedicated Endpoints.
Effortlessly fine-tune your model with Friendli Dedicated Endpoints, which leverages the Parameter-Efficient Fine-Tuning (PEFT) method to reduce training costs while preserving model quality, similar to full-parameter fine-tuning. This can make your model become an expert on a specific topic, and prevent hallucinations from your model.Table of Contents
- How to Select Your Base Model
- How to Upload Your Dataset
- How to Create Your Fine-tuning Job
- How to Monitor Progress
- How to Deploy the Fine-tuned Model
- Resources
How to Select Your Base Model
Through our (1) Hugging Face Integration and (2) Weights & Biases (W&B) Integration, you can select the base model to fine-tune. Explore and find open-source models that are supported on Friendli Dedicated Endpoints here. For guidance on the necessary format and file requirements, especially when using your own models, review the FAQ section on general requirements for a model.-
Hugging Face Model
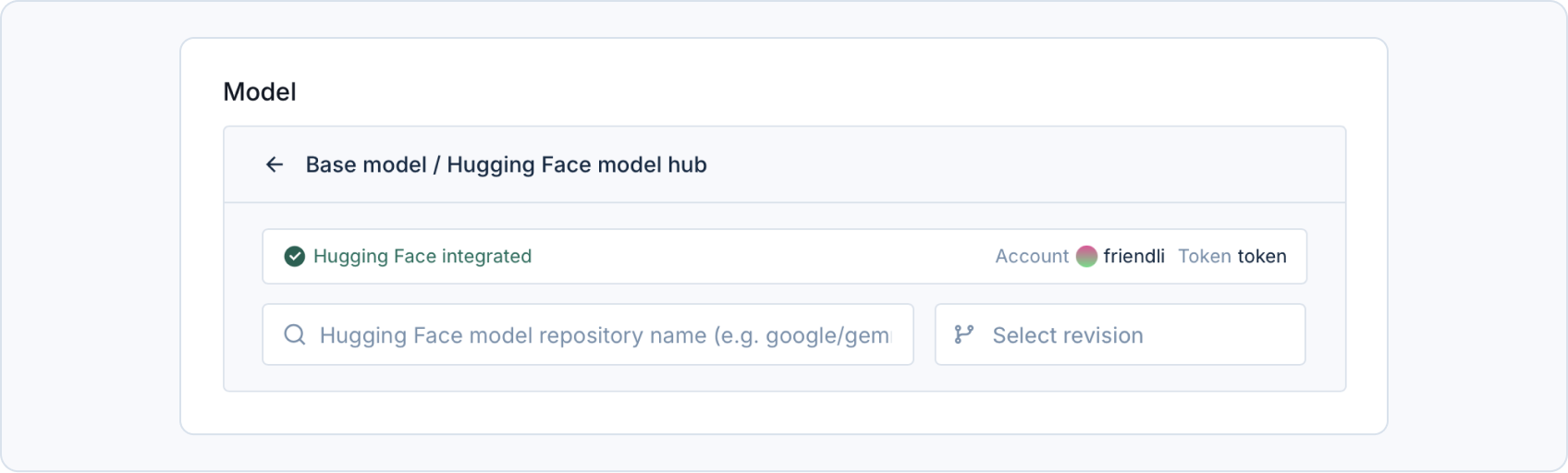
-
Weights & Biases Model
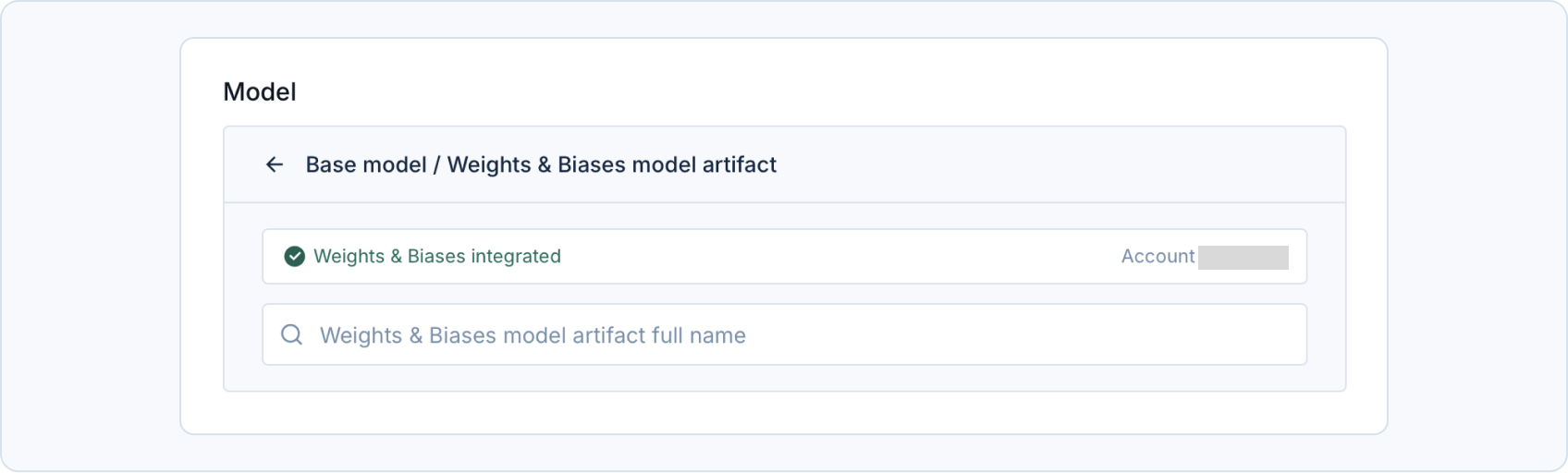
Hugging Face Integration
Integrate your Hugging Face account to access your private repo or a gated repo. Go to Personal settings > Account > Hugging Face integration and save your Hugging Face access token. This access token will be used upon creating your fine-tuning jobs.Check our FAQ section on using a Hugging Face repository as a model and
integrating a Hugging Face account for more detailed integration information.
Weights & Biases (W&B) Integration
Integrate your Weights & Biases account to access your model artifact. Go to Personal settings > Account > Weights & Biases integration and save your Weights & Biases API key, which you can obtain here. This API key will be used upon creating your fine-tuning jobs.Check our FAQ section on using a W&B artifact as a model and
integrating a W&B account for more detailed integration information.
How to Upload Your Dataset
Navigate to the ‘Datasets’ section to upload your fine-tuning dataset. Enter the dataset name, then either drag and drop your.jsonl or .parquet dataset file or browse for them on your computer.
If your files meet the required criteria, the blue ‘Upload’ button will be activated, allowing you to complete the process.
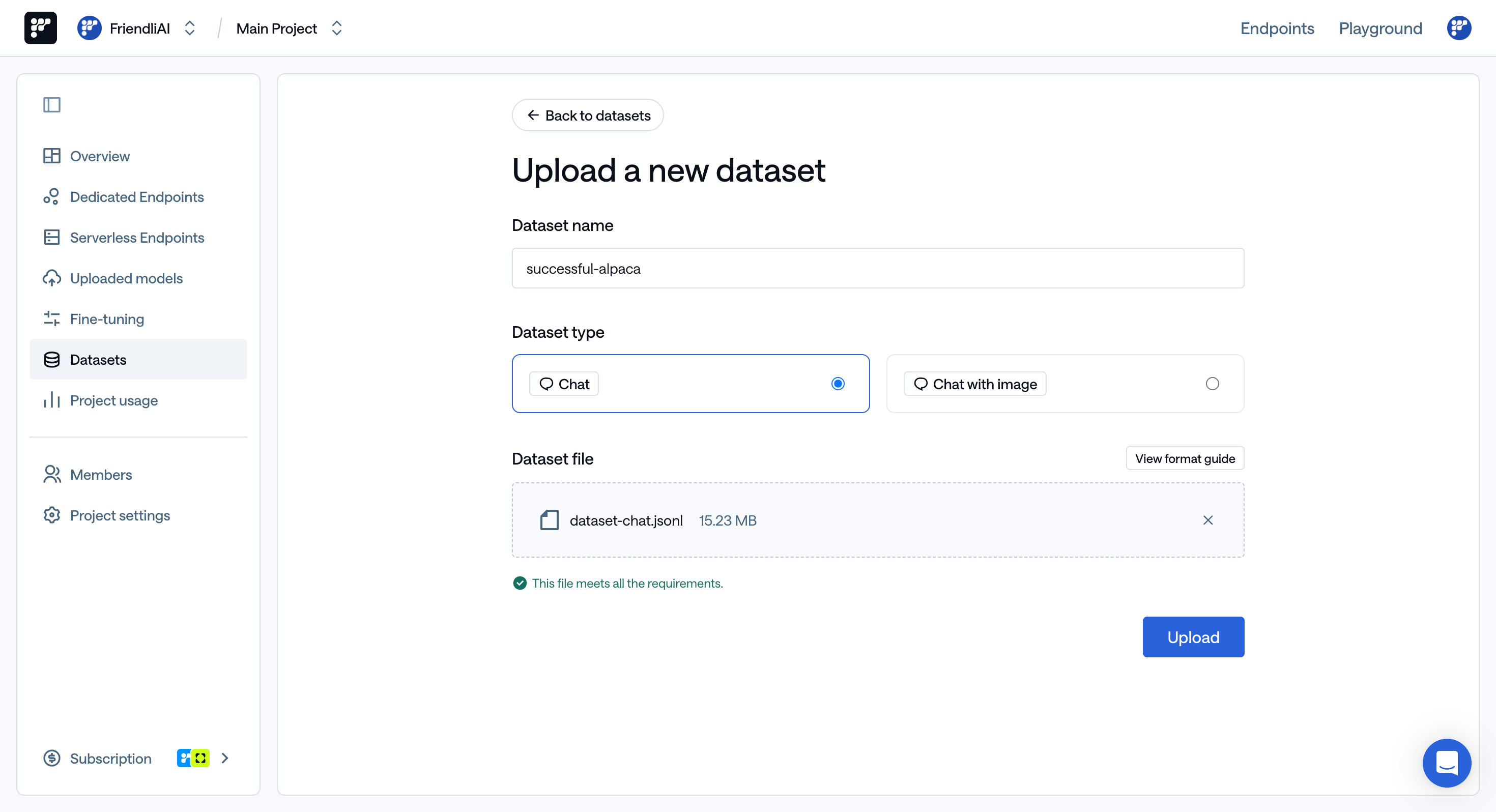
You can access our example dataset ‘FriendliAI/gsm8k’ (for Chat), ‘FriendliAI/sample-vision’ (for Chat with image) and explore some of our quantized generative AI models on our Hugging Face page.
Upload chat with image dataset via Python SDK
Install Python SDK
Upload dataset
Dataset Format
The dataset used for fine-tuning should satisfy the following conditions:- The dataset must contain a column named “messages”, which will be used for fine-tuning.
- Each row in the “messages” column should be compatible with the chat template of the base model.
For example,
tokenizer_config.jsonofmistralai/Mistral-7B-Instruct-v0.2is a template that repeats the messages of a user and an assistant. Concretely, each row in the “messages” field should follow a format like:[{"role": "user", "content": "The 1st user's message"}, {"role": "assistant", "content": "The 1st assistant's message"}]. In this case,HuggingFaceH4/ultrachat_200kis a dataset that is compatible with the chat template.
Examples
Here’s an example of what it should look like. Note that it’s one line but beautified for readability:How to Create Your Fine-tuning Job
Navigate to the ‘Fine-tuning’ section to launch and view your fine-tuning jobs. You can view the training progress in a job’s detail page by clicking on the fine-tuning job. To create a new fine-tuning job, follow these steps:- Go to your project and click on the Fine-tuning tab.
- Click ‘New job’.
- Fill out the job configuration based on the following field descriptions:
- Job name: Name of fine-tuning job to create.
- Model: Hugging Face Models repository or Weights & Biases model artifact name.
- Dataset: Your uploaded fine-tuning dataset.
- Weights & Biases (W&B): Optional for W&B integration.
- W&B project: Your W&B project name.
- Hyperparameters: Fine-tuning Hyperparameters.
Learning rate: Initial learning rate for AdamW optimizer.Batch size: Total training batch size.- Total number of training: Configure the number of training cycles with either
Number of training epochsorTraining steps.Number of training epochs: Total number of training epochs.Training steps: Total number of training steps.
Evaluation steps: Number of steps between model evaluation using the validation dataset.LoRA rank: The rank of the LoRA parameters (optional).LoRA alpha: Scaling factor that determines the influence of the low-rank matrices during fine-tuning (optional).LoRA dropout: Dropout rate applied during fine-tuning (optional).
- Click the ‘Create’ button to create a job with the input configuration.
How to Monitor Progress
After launching the fine-tuning job, you can monitor the job overview, including progress information and fine-tuning configuration. If you have integrated your Weights & Biases (W&B) account, you can also monitor the training status in your W&B project. Read our FAQ section on using W&B with dedicated fine-tuning to learn more about monitoring you fine-tuning jobs on their platform.How to Deploy the Fine-tuned Model
Once the fine-tuning process is complete, you can immediately deploy the model by clicking the ‘Deploy’ button in the top right corner. The name of the fine-tuned LoRA adapter will be the same as your fine-tuning job name.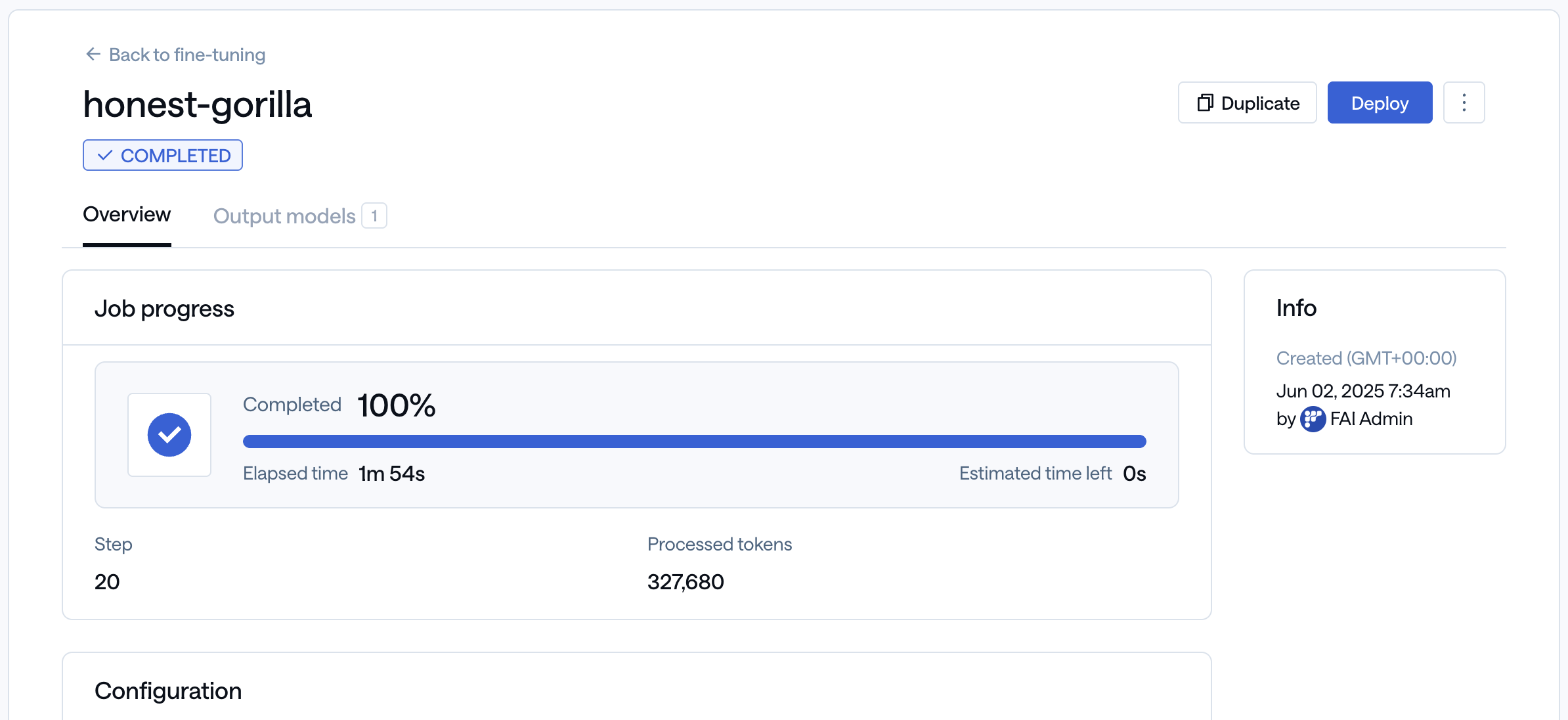
Resources
- Supported open-source models
- ‘FriendliAI/gsm8k’ on Hugging Face
- FAQ on general requirements for a model
- FAQ on using a Hugging Face repository as a model
- FAQ on integrating a Hugging Face account
- FAQ on using a W&B artifact as a model
- FAQ on integrating a W&B account
- FAQ on using W&B with dedicated fine-tuning
- Endpoints documentation on model deployment